3.5.4 上下文管理:让 AI 记住你说过的话
经过本节学习,你将掌握
- 理解 AI 的「记忆」是如何工作的
- 识别上下文「溢出」的信号
- 四个实用的上下文管理技巧
- 使用工具级配置让 AI「自动记住」项目规范
AI 的「记忆」是如何工作的
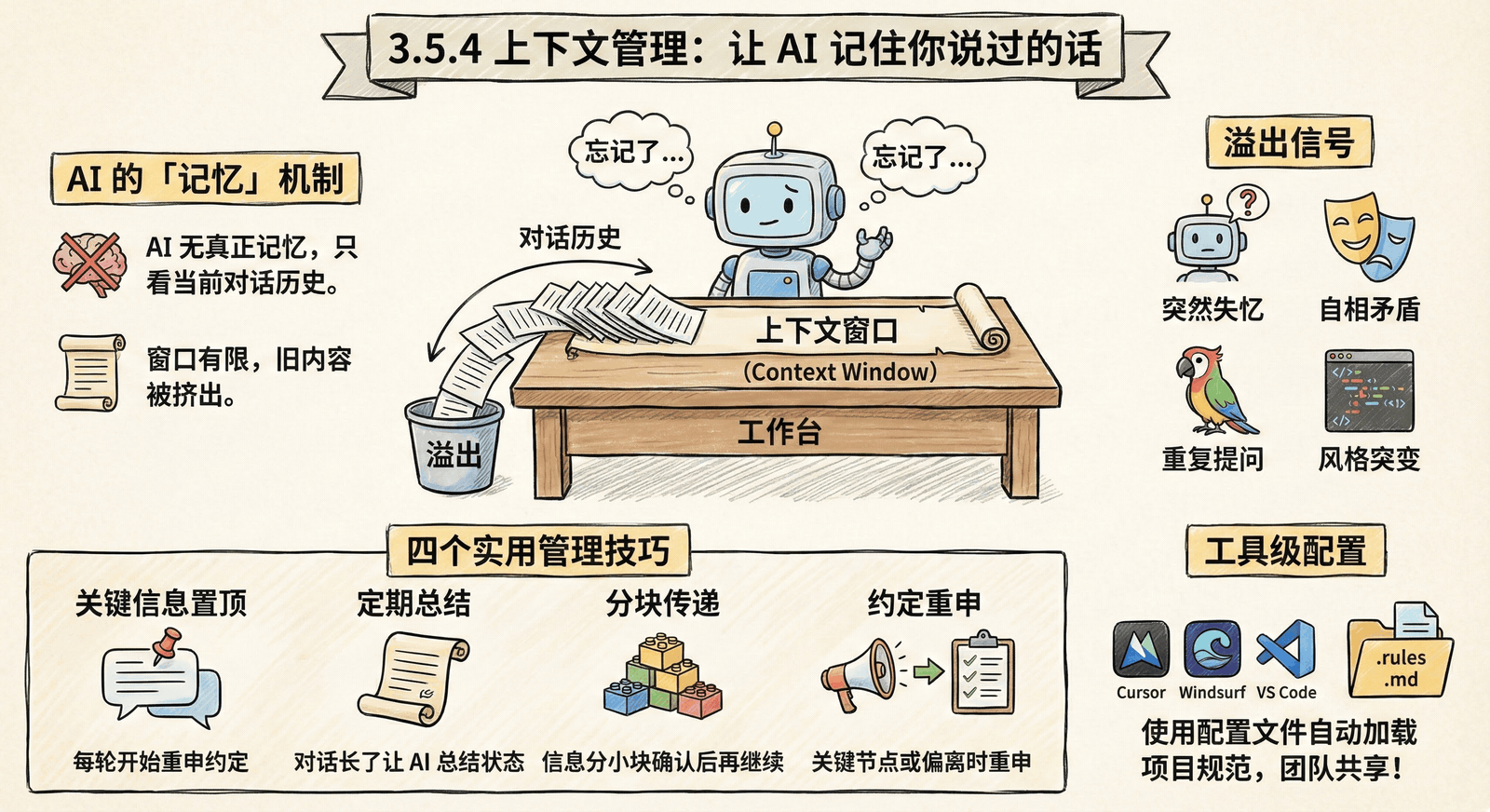
先来理解一个关键概念:AI 并没有真正的「记忆」。
每次你和 AI 对话时,AI 看到的是整个对话历史。就像你把一叠纸递给一个人,让他读完后回答问题。纸越多,他需要处理的信息就越多。
这叠「纸」有个名字:上下文窗口。
用「工作台」来理解
想象 AI 的上下文窗口是一张工作台:
┌────────────────────────────────────────────┐
│ AI 的工作台 │
│ ┌──────┐ ┌──────┐ ┌──────┐ ┌──────┐ │
│ │ 第1轮 │ │ 第2轮 │ │ 第3轮 │ │ 第4轮 │ ... │
│ │ 对话 │ │ 对话 │ │ 对话 │ │ 对话 │ │
│ └──────┘ └──────┘ └──────┘ └──────┘ │
│ │
│ 工作台大小有限(如 128K tokens) │
└────────────────────────────────────────────┘工作台的特点:
- 大小有限(不同模型不同,通常 8K-200K tokens)
- 放不下时,最早的内容会被「挤出去」
- 被挤出去的内容,AI 就「忘记」了
不同模型的上下文窗口大小
| 模型 | 上下文窗口 | 大约相当于 |
|---|---|---|
| GPT-4o | 128K tokens | 约 300 页文档 |
| Claude 3.5 Sonnet | 200K tokens | 约 500 页文档 |
| DeepSeek | 64K tokens | 约 150 页文档 |
| 较老的模型 | 4K-8K tokens | 约 10-20 页文档 |
看起来很大?但在长对话中,消耗速度比你想象的快。
上下文「溢出」的信号
当对话太长,早期内容被挤出上下文窗口时,就会出现「溢出」。
常见症状
| 症状 | 表现 | 原因 |
|---|---|---|
| AI 无法访问早期对话 | 忘记之前约定的技术栈或命名规范 | 早期对话被挤出 |
| 输出不一致 | 前后回答不一致 | 只看到部分历史 |
| 重复问你问过的问题 | "请问你用的是什么框架?"(之前说过了) | 那部分对话已不在窗口内 |
| 代码风格突变 | 之前用 TypeScript,突然开始写 JavaScript | 忘记了技术栈约定 |
一个真实场景
第 1 轮:你说"请用 TypeScript 和 Tailwind"
第 2 轮:AI 用 TypeScript 写代码
第 3 轮:继续用 TypeScript
...
第 15 轮:你让 AI 写一个新组件
第 16 轮:AI 突然给你 JavaScript 代码 ← 问题出现这就是上下文溢出。第 1 轮的约定已经被挤出工作台了。
四个上下文管理技巧
技巧一:关键信息置顶
在每轮对话开始时,重申关键约定。
markdown
继续我们的待办清单项目。
提醒:
- 技术栈:React + TypeScript + Tailwind
- 命名规范:组件用 PascalCase,函数用 camelCase
- 所有函数需要类型声明
现在请帮我实现 [新功能]...效果:关键信息始终在 AI 的「视野」中。
技巧二:定期总结
当对话进行到 10 轮以上时,主动让 AI 总结已完成的工作。
markdown
我们已经聊了很多轮。请总结一下目前的项目状态:
1. 已完成的功能
2. 使用的技术栈和约定
3. 待完成的功能
然后我们继续开发。效果:
- 把散落在各处的信息「压缩」成一段总结
- 总结在最新位置,不会被挤出
- 你也可以确认 AI 的理解是否正确
技巧三:分块传递
不要一次性发送大量信息。分成多个小块,每块确认 AI 理解后再继续。
❌ 错误做法:
一次性发送 3000 字的需求文档
✅ 正确做法:
第一条消息:"我要做一个待办清单应用,先来定义核心数据结构..."
等 AI 回复确认后
第二条消息:"数据结构定好了,接下来是主要功能列表..."效果:
- 每块信息都得到充分处理
- 减少 AI 遗漏信息的概率
- 便于及时发现理解偏差
技巧四:约定重申
在关键节点重申重要约定,尤其是:
- 开始新功能时
- 发现 AI 偏离约定时
- 对话超过 10 轮时
markdown
开始新功能之前,确认一下我们的约定:
1. 使用 TypeScript,不使用 any 类型
2. 组件放在 src/components 目录
3. 状态管理使用 useState,复杂状态用 useReducer
4. 错误处理使用 try-catch
确认后,请开始实现 [功能]。上下文管理实用模板
对话开始时的上下文设定
markdown
项目背景:
- 项目名称:[名称]
- 技术栈:[技术栈列表]
- 当前进度:[简要描述]
本次任务:
[具体任务描述]
请注意以下约定:
1. [约定1]
2. [约定2]
3. [约定3]长对话中途的「检查点」
markdown
暂停一下,让我确认当前状态:
已完成:
1. [功能1]
2. [功能2]
使用的技术/约定:
- [约定1]
- [约定2]
接下来要做:
[下一个任务]
以上理解正确吗?确认后继续。约定违反时的纠正
markdown
注意:刚才的代码使用了 JavaScript,但我们项目约定使用 TypeScript。
请重新生成,并确保:
1. 所有变量和函数都有类型声明
2. 不使用 any 类型
3. 导出类型定义供其他组件使用工具级上下文管理
除了在对话中管理上下文,主流 AI IDE 还提供了持久化配置功能。这些配置会在每次对话开始时自动加载,让 AI「天生」就知道你的项目规范。
主流工具的配置文件对照表
| 工具 | 配置文件位置 | 功能定位 |
|---|---|---|
| Cursor | .cursor/rules/*.mdc | 项目规范、编码风格、技术栈偏好 |
| Windsurf | .windsurf/rules/*.md 或 .windsurfrules | 项目级 AI 行为规则 |
| Trae | .trae/project_rules.md、user_rules.md | 用户规则 + 项目规则 |
| Claude Code | CLAUDE.md + SKILL.md | 项目上下文 + 可复用技能 |
| GitHub Copilot | .github/copilot-instructions.md | 仓库级指令 |
| OpenAI Codex | AGENTS.md | 代理指令文件 |
| Factory Droid | .factory/droids/*.md | 自定义 Droid 配置 |
| Aider | CONVENTIONS.md | 编码规范文件 |
| Cline | .clinerules | 项目规则 |
配置文件应该写什么?
无论使用哪个工具,配置文件通常包含:
- 项目概述:这是什么项目,解决什么问题
- 技术栈:使用的语言、框架、库
- 编码规范:命名约定、代码风格、目录结构
- 禁止事项:不要使用的库、不要采用的模式
- 常用命令:构建、测试、部署的命令
通用项目配置模板
markdown
# 项目配置
## 项目概述
这是一个待办清单应用,帮助用户管理日常任务。
## 技术栈
- 前端:React 18 + TypeScript 5
- 样式:Tailwind CSS 3
- 状态管理:Zustand
- 测试:Vitest
## 目录结构
- src/components:React 组件
- src/hooks:自定义 Hooks
- src/utils:工具函数
- src/types:TypeScript 类型定义
## 编码规范
- 使用函数式组件,不用 class 组件
- 所有函数必须有 TypeScript 类型声明
- 组件文件使用 PascalCase 命名
- 工具函数使用 camelCase 命名
- 使用中文注释
## 禁止事项
- 不要使用 `any` 类型
- 不要使用 jQuery
- 不要在组件中直接写内联样式(使用 Tailwind)
- 不要使用 `var`,使用 `const` 或 `let`
## 常用命令
- 开发:npm run dev
- 构建:npm run build
- 测试:npm test为什么配置文件很重要?
| 没有配置文件 | 有配置文件 |
|---|---|
| 每次对话都要重复说技术栈 | AI 自动知道技术栈 |
| AI 可能用错误的规范 | 规范始终一致 |
| 团队成员各自配置不同 | 团队共享同一份配置 |
| 约定容易被遗忘 | 约定被版本控制 |
提示:具体工具的详细配置方法,请参考各工具的官方文档。基础版只需了解这些功能存在即可,进阶版会有更详细的工具配置教程。
本节要点
✓ AI 无真正记忆:它看到的是对话历史,历史太长会「溢出」
✓ 溢出信号:AI 无法访问早期对话、输出不一致、代码风格突变
✓ 四个管理技巧:关键信息置顶、定期总结、分块传递、约定重申
✓ 工具级配置:用配置文件让 AI 自动加载项目规范
✓ 团队协作:配置文件可纳入版本控制,团队共享
下一节,我们来学习什么时候应该放弃旧对话,开始一个全新的对话。