3.5 迭代对话的艺术:从「一次搞定」到「逐步逼近」
本节目标:掌握多轮对话技巧,学会在对话中逐步逼近理想结果
你已经学会了写结构化的提示词(3.2),掌握了进阶技巧(3.3),甚至能写出一份完整的 PRD(3.4)。但当你把这些都交给 AI 后,很可能发现:第一次输出往往不是你想要的。
这不是你的问题,也不是 AI 的问题。这是对话的本质。
核心洞见
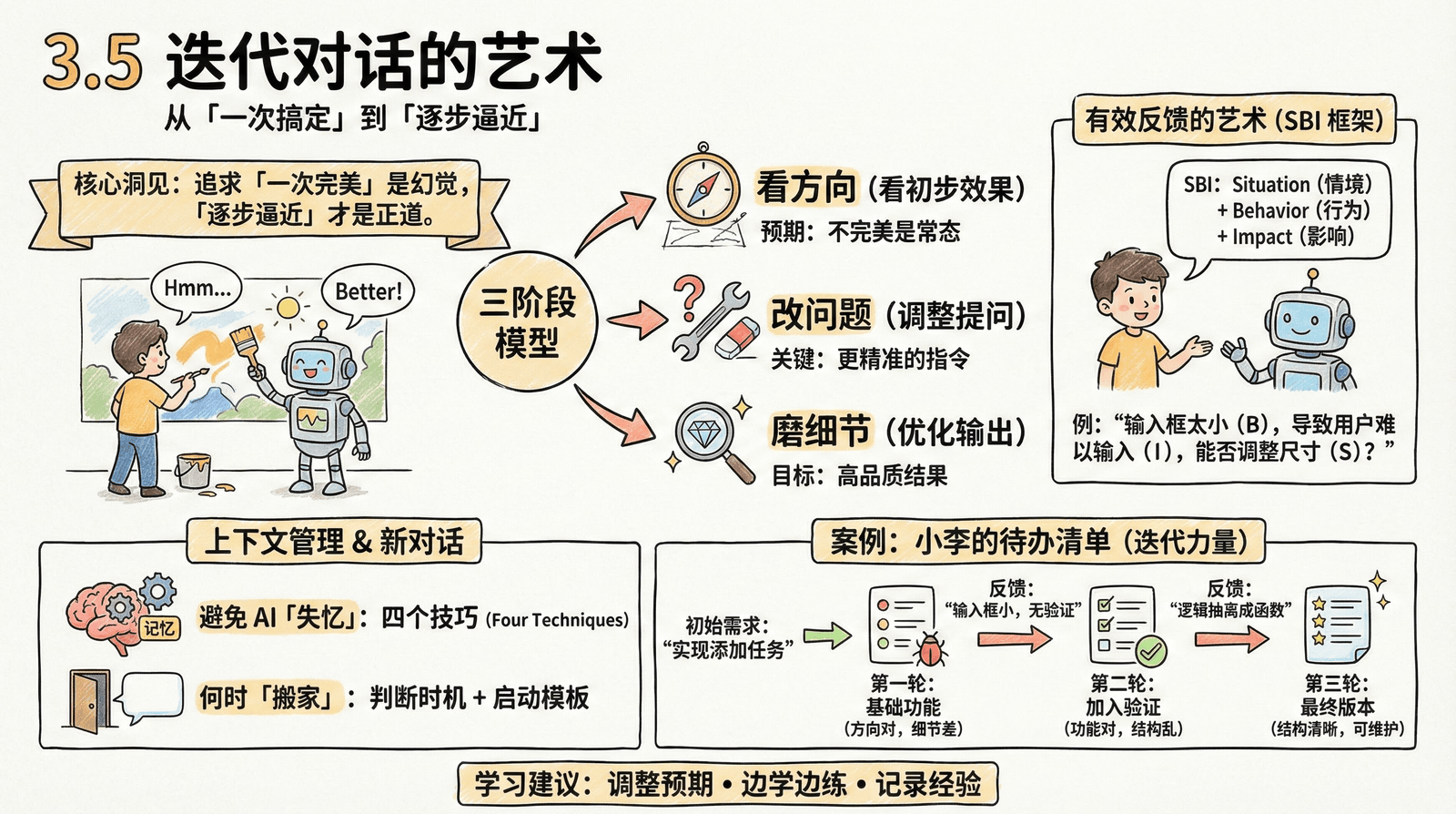
"追求「一次完美」是幻觉,「逐步逼近」才是正道。"
想象你在装修房子。你不会期望油漆工刷完第一遍就完美无瑕。你会看效果、提意见、再调整。AI 对话也是如此——它是一个协作过程,不是一次命令执行。
经过本节学习,你将掌握
- 理解为什么「一次提问」往往不够
- 掌握迭代对话的三阶段模型:看方向 → 改问题 → 磨细节
- 学会用 SBI 框架给 AI 有效反馈
- 管理长对话的上下文,避免 AI「失忆」
- 知道何时该开始新对话,以及如何「搬家」
本节在第三章中的位置
3.1 提示词基础 → 知道该告诉 AI 什么信息
↓
3.2 结构化框架 → 学会如何组织这些信息
↓
3.3 进阶技巧 → 掌握不同的「问法」
↓
3.4 第一份 PRD → 整合思考,形成任务书
↓
3.5 迭代对话(本节) → 在执行中逐步调整,逼近理想结果
↓
3.6 Debug 策略 → 当 AI 出错时如何修正如果说 3.1-3.4 是教你「怎么开好头」,本节就是教你「怎么跑完全程」。
本节结构
| 小节 | 核心内容 | 你会获得 |
|---|---|---|
| 3.5.1 | 为什么一次提问往往不够 | 正确预期:迭代是常态,不是失败 |
| 3.5.2 | 迭代对话的基本模式 | 三阶段模型 + 完整对话示例 |
| 3.5.3 | 有效反馈的艺术 | SBI 框架 + 反馈句式库 |
| 3.5.4 | 上下文管理 | 避免 AI「失忆」的四个技巧 |
| 3.5.5 | 知道何时开始新对话 | 「搬家」时机判断 + 启动模板 |
延续案例:小李的待办清单
本节继续使用小李的待办清单项目。你会看到一个完整的迭代过程:
初始需求:"帮我实现添加任务的功能"
↓
第一轮:AI 给出基础实现(方向对,但细节差)
↓
反馈:"输入框太小,而且没有验证空输入"
↓
第二轮:AI 修正,加入验证(功能对,但结构不满意)
↓
反馈:"验证逻辑放在了组件里,我希望抽成独立函数"
↓
第三轮:最终版本(结构清晰,可维护)三轮对话,从「能用」到「好用」。这就是迭代的力量。
学习建议
- 调整预期:第一轮输出不完美是正常的,不要沮丧
- 边学边练:每个小节都有可复制的模板,建议实际使用
- 记录经验:把有效的反馈句式收集起来,形成自己的「武器库」
准备好了吗?让我们从「为什么一次提问往往不够」开始。